 LMQL
LMQLOpenAI
LMQL also supports models available via the OpenAI Completions or Chat API, e.g., GPT-3.5 variants, ChatGPT, and GPT-4. LMQL also supports Azure OpenAI models, discussed in more detail in Azure OpenAI.
The following models were tested to work with LMQL, with the corresponding model identifier being used as lmql.model(...) or in the from clause of a query:
Completions API
openai/text-ada-001openai/text-curie-001openai/text-babbage-001openai/text-davinci-00[1-3]openai/gpt-3.5-turbo-instruct
Chat API Support
openai/gpt-3.5-turboalso available aschatgptopenai/gpt-4also available asgpt-4
Chat API Limitations
Due to API limitations, Chat API models do not offer full support for LMQL constraints. The reason for this is that the Chat API in its current form is too restrictive. Nevertheless, simple constraints such as STOPS_AT, STOPS_BEFORE, and len(TOKENS(...)) < N are still available, as well as LMQL's other features such as intermediate instructions and scripted prompting.
For more details on the limitations of the Chat API, please refer to the OpenAI API Limitations section.
Configuring OpenAI API Credentials
If you want to use OpenAI models, you have to configure your API credentials. To do so you can either define the OPENAI_API_KEY environment variable:
export OPENAI_API_KEY=<your key>
or create a file api.env in the active working directory, with the following contents:
openai-org: <org identifier>
openai-secret: <api secret>
For system-wide configuration, you can also create an api.env file at $HOME/.lmql/api.env or at the project root of your LMQL distribution (e.g. src/ in a development copy).
Lastly, you can also use LMQL-specific environment variables LMQL_OPENAI_SECRET and LMQL_OPENAI_ORG, which take precedence over the OPENAI_API_KEY environment variable.
Monitoring OpenAI API use
When working with OpenAI models, it is important to keep track of your API usage. LMQL offers a couple of ways to see what is happening internally and how many API calls are being made.
Playground
In the playground in the bottom right of the query editor, you can see real-time query statistics, including no. of requests, tokens and estimated cost when using OpenAI models:
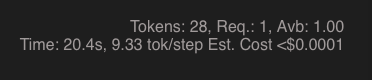
This information is automatically updated as your query is being executed. If you want to see the same information in Python, you can use the following snippet.
Usage Statistics in Python
To obtain the same information in Python, you can use the following snippet:
from lmql.runtime.bopenai import get_stats
print(get_stats())
# OpenAI API Stats: 1 requests, 0 errors, 9 tokens, 1.0 average batch size
The tokens metric here refers to the number of tokens that were consumed and generated by the model.
API Request Logging
Additionally, you may be interested in seeing the actual API requests that are made in the background. To show these, there is a decoder option verbose=True, which enables verbose logging and will print all OpenAI request payloads console, e.g. a query like this:
argmax(verbose=True) "Hello[WHO]" from "openai/text-ada-001" where STOPS_AT(WHO, "\n")
model-output::
Completion with {'model': 'text-ada-001', 'prompt': \[550256, 15496], 'max_tokens': 64, 'temperature': 0, 'logprobs': 5, 'user': 'lmql', 'stream': True, 'echo': True}
Configuring Speculative OpenAI API Use
To integrate the OpenAI API with LMQL, we rely on speculative prediction, where LMQL applies token masking and stopping conditions less eagerly, to save API calls.
To achieve this, output is generated in chunks, where each chunk is verified to satisfy the constraints before generation continues. The chunk size can be configured by passing chunksize parameter in the decoding clause like so:
argmax(chunksize=128)
"The quick brown fox jumps over the[COMPLETION]"
from
"openai/text-ada-001"
where
STOPS_AT(COMPLETION, ".")
By default, the chunk size is set to 32. This value is chosen based on the consideration, that a very large chunk size means that LMQL potentially has to discard many generated tokens (which is expensive), if a constraint is violated early on. However, if a query has few or only stopping phrase constraints, a larger chunk size may be beneficial for overall query cost. In general, if a query requires multiple long, uninterrupted sequences to be generated without imposing many constraints, a larger chunk size is recommended.
OpenAI API Limitations
Unfortunately, the OpenAI API Completions and Chat API are severely limited in terms of token masking and the availability of the token distribution per predicted token. LMQL tries to leverage these APIs as much as possible, but there are some limitations that we have to work around and may affect users:
The OpenAI Completion API limits the number of possible logit biases to 300. This means, if your constraints induce token masks that are larger than 300 tokens, LMQL will automatically truncate the token mask to the first 300 tokens. This may lead to unexpected behavior, e.g., model performance may be worse than expected as the masks are truncated to be more restrictive than necessary. In cases where the 300 biases limit is exceeded, LMQL prints a warning message to the console, indicating that the logit biases were truncated.
The OpenAI Completions API only provides the top-5 logprobs per predicted token. This means that decoding algorithms that explore e.g. the top-n probabilities to make decisions like beam search, are limited to a branching factor of 5.
The OpenAI Chat API does not provide a way to obtain token distributions or generate/continue partial responses (ChatGPT, GPT-4). Simple constraints can still be enforced, as the LMQL runtime optimizes them to fit the OpenAI API. However, more complex constraints may not be enforceable. In these cases, LMQL will print a error message to the console. As a workaround users may then adjust their constraints to fit these API limitations or resort to post-processing and backtracking. Scripted prompting, intermediate instructions and simple constraints are still supported with Chat API models, nonetheless.